Microsoft Fabric update september 2025: AI-integraties, betere governance en meer!
Maarten Gerritsen
October 13, 2025
De Microsoft Fabric-update voor september 2025 brengt diverse verbeteringen in data governance, gebruiksvriendelijkheid en AI-integraties. OneLake (de centrale data-opslag van Fabric) krijgt een speciaal Govern-overzicht, de ontwikkelervaring wordt versterkt met een multitasking-UI, en data engineers en analisten kunnen profiteren van snellere dataflows en nieuwe mogelijkheden in notebooks. In deze nieuwsbrief lichten we de belangrijkste vernieuwingen toe voor Platform, Data Engineering, Data Science, Real-Time Intelligence en Data Factory. Meer informatie over hoe Microsoft Fabric jouw organisatie kan helpen? Bekijk onze Microsoft Fabric diensten.
Microsoft heeft deze maand flink ingezet op het verbeteren van de governance en ontwikkelaarservaring binnen Fabric. Van een centraal overzicht voor data governance tot een volledig vernieuwde interface voor multitasking, deze updates maken het platform krachtiger en gebruiksvriendelijker.
• Govern-tab in OneLake Catalog (algemeen beschikbaar): OneLake (de "OneDrive voor data" binnen Fabric) heeft nu een Govern-tabblad dat algemeen beschikbaar is. Deze biedt een hoogover overzicht van data governance in je Fabric-omgeving, met dashboards en inzichten over al je gegevensobjecten. Data-eigenaren krijgen hier aanbevelingen voor het verbeteren van governance en kunnen in één centrale plek zaken regelen als toegang, policies en beveiliging. Dit verhoogt de zichtbaarheid en controle over data, wat vooral nuttig is nu organisaties meer domain-based data governance willen invoeren.
• Variabele bibliotheek (algemeen beschikbaar): De Fabric Variable Library is nu algemeen beschikbaar. Hiermee kun je op workspace-niveau variabelen definiëren en beheren, bijvoorbeeld om omgevingsspecifieke instellingen (dev/test/prod) centraal op te slaan. Nieuw is dat variabelen niet meer beperkt zijn tot deployment pipelines: je kunt ze nu ook gebruiken in Dataflow Gen2 dataflows en in Copy pipeline activiteiten. Door één keer een waarde aan te passen in de variabelenbibliotheek kun je meteen alle gekoppelde datasets, flows of notebooks laten verwijzen naar de juiste bron of parameter. Een enorme vereenvoudiging voor CI/CD en configuratiebeheer over meerdere omgevingen.
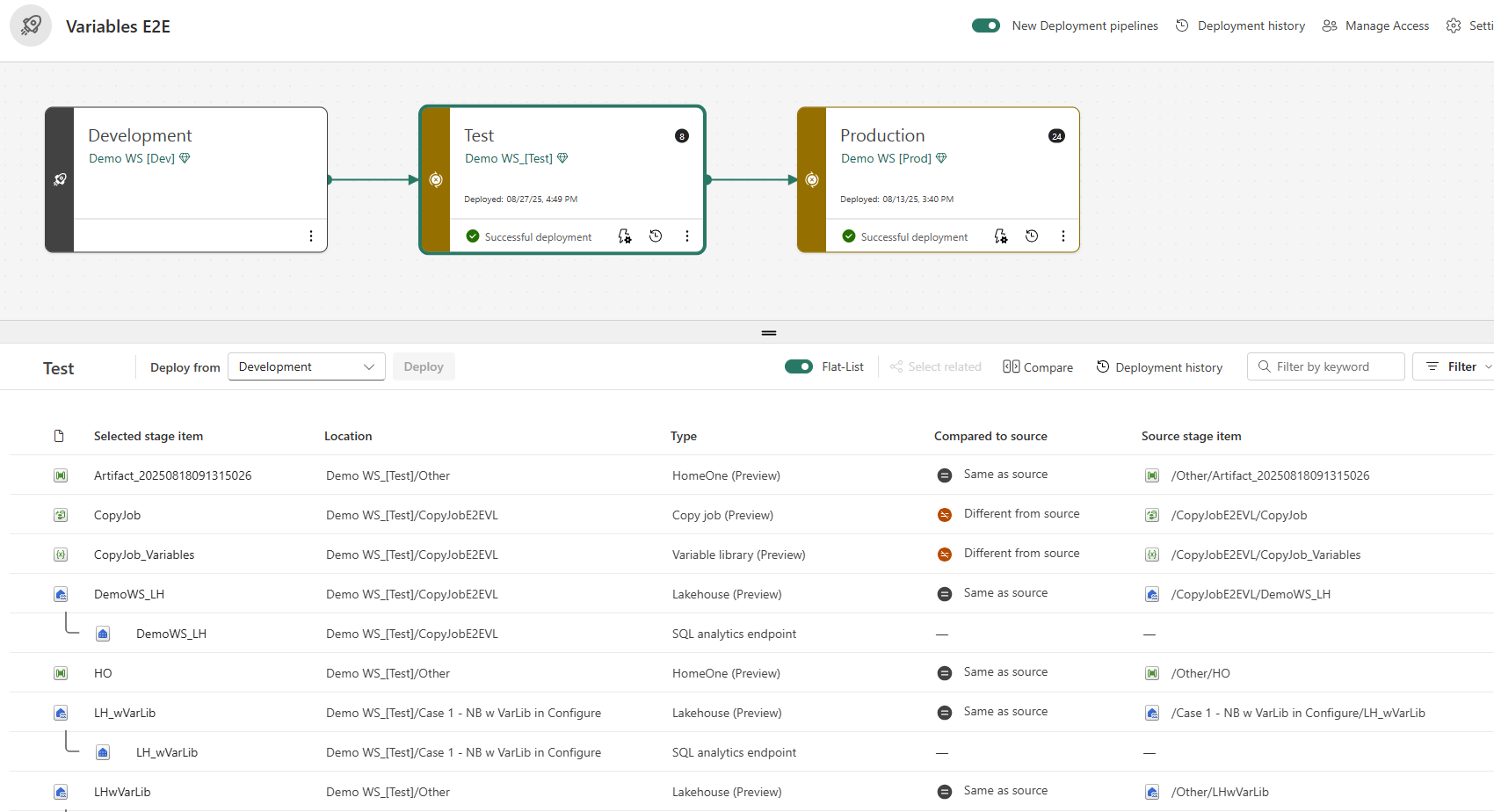
• Nieuw ontwerp voor Deployment Pipelines (algemeen beschikbaar): De release omvat een volledig herontwerp van de Deployment Pipeline-interface, nu algemeen beschikbaar. Deze visuele update maakt het beheren van je ontwikkel-test-productie pipelines een stuk intuïtiever. Het nieuwe ontwerp biedt een duidelijker overzicht van de werkruimtes per stage, verbeterde weergave van verschillen, en een modernere look-and-feel die aansluit bij de Fabric-portal. Dit betekent minder zoeken en makkelijker deployments doorvoeren, omdat je in één oogopslag ziet welke content waar klaarstaat om gepromoveerd te worden.
• Fabric MCP (preview): Fabric MCP staat voor Model Context Protocol, een ontwikkelaarsgerichte server die AI-assistenten laat samenwerken met Fabric. In preview kun je nu deze MCP-server inzetten om bijvoorbeeld code of items in Fabric te laten genereren via tools als GitHub Copilot. Denk aan een scenario waar je in VS Code tegen Copilot zegt: "maak een nieuwe Lakehouse aan in Fabric", waarna de MCP-server dit begrijpt en uitvoert. Deze functie sluit aan op de trend van AI-ondersteunde development: het automatiseert repeterende handelingen en maakt het makkelijker om Fabric-artefacten te creëren met behulp van slimme AI-assistenten.
• Multitasken in de Fabric-portal (preview): Fabric Multitasking Gets a Developer-Friendly Upgrade is de naam van een grote UI-verandering: je kunt nu meerdere items tegelijk openen in tabbladen, maar alleen in de nieuwe Fabric-portal (app.fabric.microsoft.com). In plaats van beperkt te zijn tot één rapport of notebook per venster, kun je in de Fabric-UI nu net als in een webbrowser of IDE meerdere tabs bovenin hebben met verschillende artefacten. Elke geopende workspace krijgt zijn eigen kleuraanduiding in de tab, zodat je visueel onderscheid hebt tussen bijvoorbeeld een rapport uit de ene workspace en een notebook uit een andere. Het resultaat: een veel soepelere ervaring voor ontwikkelaars en power users die tussen verschillende onderdelen willen schakelen.
Voor data engineers brengt september flink wat verbeteringen in flexibiliteit en performance. Van User Data Functions tot realtime monitoring in notebooks, deze updates maken het werk efficiënter en transparanter.
• Fabric User Data Functions: updates & notebook-integratie (algemeen beschikbaar): User Data Functions (UDFs) in Fabric zijn nu production-ready en hebben een aantal verbeteringen gekregen. UDFs kun je zien als door de gebruiker gedefinieerde routines (in bijvoorbeeld Python) die je binnen Fabric pipelines of dataflows kunt hergebruiken voor complexe logica. Nieuw is de nauwere integratie met notebooks: je kunt UDF-code ontwikkelen en testen in een Fabric Notebook-omgeving, inclusief ondersteuning voor Pandas DataFrames, en deze functies vervolgens als onderdeel van je data pipeline aanroepen. Dit maakt UDF's een stuk gebruiksvriendelijker en krachtiger, omdat je de interactiviteit van notebooks kunt combineren met herbruikbare functies in je dataprocessen.
• Fabric Materialized Lake Views: nieuwe features: Materialized Lake Views (preview) bieden de mogelijkheid om versneld query's uit te voeren op data in OneLake door vooraf berekende views op te slaan. In deze update zijn nieuwe functies toegevoegd, zoals "smart refresh" (automatisch bepalen of een volledige, incrementele of geen refresh nodig is), betere inzichtelijkheid in de lineage (je ziet afhankelijkheden van de view binnen je Lakehouse), ondersteuning voor custom omgevingen voor refresh, en on-demand verversen (handmatig een view bijwerken buiten het vaste schema om). Dit zijn waardevolle verbeteringen die de performance en beheerbaarheid van Lakehouse-views vergroten.
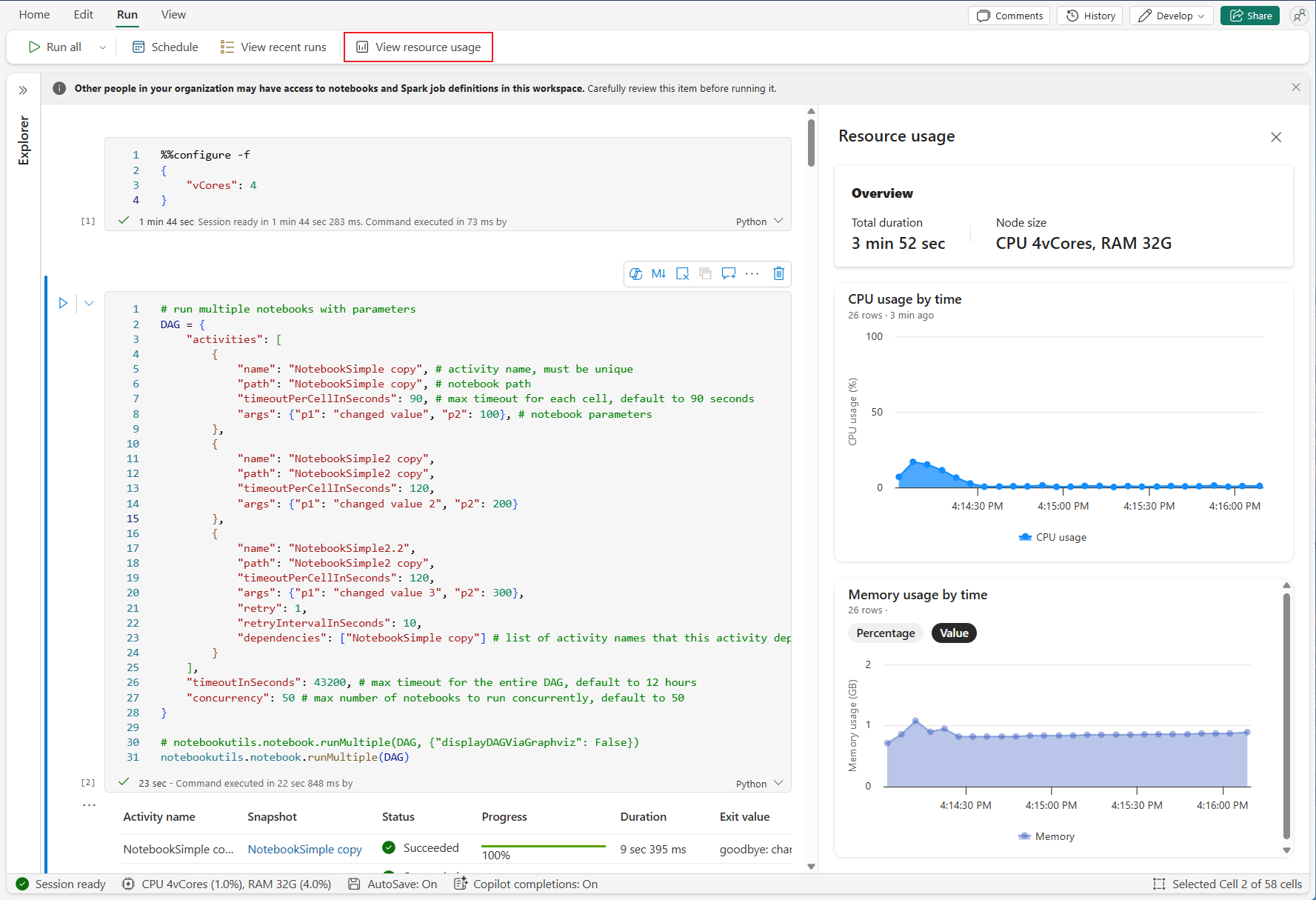
• Realtime resource-monitoring in Python notebooks: Draaien je Fabric notebooks efficiënt? Je kunt nu in pure Python-notebooks live meekijken met het verbruik van resources terwijl je code runt. In de notebookinterface is een nieuw Resource usage paneel beschikbaar (voorlopig alleen voor Python, niet voor Spark notebooks) waarin je onder andere CPU- en geheugengebruik in real-time ziet tijdens het uitvoeren van de cellen. Zo merk je meteen of een bepaalde bewerking veel geheugen opslokt of dat je code vastloopt op CPU-limieten. Dit helpt ontwikkelaars om notebooks te optimaliseren en te beslissen of zwaardere workloads misschien beter op een Spark-cluster moeten draaien.
De Data Science-mogelijkheden van Fabric krijgen een boost door uitgebreide ondersteuning voor Data Agents en externe integraties. Deze updates maken AI-gedreven analyses toegankelijker en flexibeler.
• Mirrored database support voor Fabric Data Agent: De Fabric Data Agent (de AI-gedreven "vraagbaak" die in Fabric onder andere door Copilot wordt gebruikt) kan nu direct overweg met mirrored databases. Dit houdt in dat als je externe databases hebt gespiegeld naar Fabric's OneLake (bijvoorbeeld via de nieuwe Mirroring functie), de Data Agent deze direct kan meenemen in analyses. Microsoft heeft hiermee ondersteuning toegevoegd voor direct koppelen van gemirrorde databronnen zoals Azure Cosmos DB, Azure SQL, Oracle, Snowflake en Databricks. Voor data scientists en analisten betekent dit dat AI-gestuurde vragen en inzichten nu ook actuele data uit deze externe systemen kunnen omvatten, vrijwel realtime en zonder aparte ETL.
• Fabric Data Agent extern aanroepen via Python SDK (preview): Microsoft heeft een Python client SDK uitgebracht (preview) waarmee je Fabric Data Agents kunt integreren in eigen applicaties of scripts. Concreet kun je nu buiten de Fabric webinterface om een Data Agent aanspreken, bijvoorbeeld in een Python-applicatie die je on-premises draait of in een andere cloudomgeving. Dit opent de deur naar allerlei toepassingen: van een chatbot in je website die via de Fabric Data Agent antwoorden uit je bedrijfsdata haalt, tot geautomatiseerde analyses in een notebook die vragen stelt aan de Data Agent en de resultaten verwerkt. Zo wordt Fabric's AI-functionaliteit nog toegankelijker voor ontwikkelaars.
Real-Time Intelligence krijgt een opvallende toevoeging met Maps in Fabric, waarmee locatiegegevens direct visueel gemaakt kunnen worden zonder complexe externe tools.
• Maps in Fabric: Met deze feature kun je nu locatiegegevens direct op een kaart visualiseren, zonder daarvoor externe tools of ingewikkelde code nodig te hebben. Iedereen (van data citizen tot BI-specialist) kan met een paar klikken een map aanmaken op basis van data in een Lakehouse of Eventstream, compleet in Fabric stijl. Denk hierbij aan het realtime plotten van sensordata op een plattegrond, of het weergeven van verkoopcijfers per regio in een interactieve kaartvisual. De Maps-functionaliteit is ontworpen als no-code ervaring: je selecteert je dataset met bijvoorbeeld coördinaten of adressen, en Fabric verzorgt de weergave. Dit maakt geospatiale analyses een stuk toegankelijker.
Ondanks dat onze voorkeur toch echt naar Notebooks met PySpark en/of SparkSQL scripts gaat, zijn er toch wat interessante updates binnen een van de andere mogelijkheden die Fabric biedt. Data Factory krijgt krachtige performance-updates en nieuwe functies die het werken met dataflows aanzienlijk versnellen en flexibeler maken.
• Partitioned Compute voor Dataflows (preview): Dataflows Gen2 (de moderne versie van Power Query pipelines in Fabric) krijgen een aanzienlijke performance-boost dankzij partitioned compute. Deze nieuwe functie maakt het mogelijk om delen van de data-transformatie parallel uit te voeren. Waar voorheen bepaalde stappen sequentieel werden afgehandeld, kan Fabric nu stukken van je dataflow gelijktijdig evalueren. Het resultaat is dat door parallelle verwerking grote dataflows tot wel een factor 10 sneller kunnen draaien in sommige scenario's. Voor data engineers betekent dit kortere wachttijden bij het verwerken van grote datasets en efficiënter gebruik van onderliggende compute-resources.
• Preview-Only Steps (preview): Bij het bouwen van een dataflow wil je soms een tussenstap toevoegen om bijvoorbeeld data te filteren of sample-gegevens te bekijken tijdens het ontwikkelen, maar je wilt niet dat die stap in de productie-run ook wordt uitgevoerd. Preview-Only steps lossen dit op. Je kunt een transformatiestap markeren als "alleen preview", waardoor deze wel zichtbaar en toepasbaar is tijdens het designen (voor bijvoorbeeld een voorbeelddataset of troubleshooting), maar automatisch wordt overgeslagen bij de echte uitvoering van de dataflow. Dit maakt de ontwikkelervaring een stuk soepeler: je hoeft niet langer tijdelijke filterstappen steeds handmatig aan en uit te zetten.
• Incremental refresh naar Lakehouse (algemeen beschikbaar): Goed nieuws voor scenario's waarin je continu data bijwerkt: Dataflow Gen2 ondersteunt nu incremental refresh direct naar een Lakehouse als bestemming. Voorheen kon je incremental refresh vooral met Power BI-datasets gebruiken, maar nu kun je ook een Dataflow instellen om alleen gewijzigde of toegevoegde gegevens naar een Fabric Lakehouse te schrijven. Dit is per september algemeen beschikbaar. In de praktijk betekent dit dat je niet meer elke run alle data hoeft te verwerken; in plaats daarvan worden alleen de nieuwe of gewijzigde records sinds de laatste run in het Lakehouse geüpdatet. Dit bespaart enorm op verwerkingstijd en compute-kosten, zeker bij grote historische tabellen.
De september 2025 update van Microsoft Fabric staat in het teken van een nog krachtiger dataplatform voor zowel ontwikkelaars als eindgebruikers. Van een geïntegreerd governance-dashboard in OneLake tot een ontwikkelaarsvriendelijke UI met tabbladen, en van slimmere dataflows tot AI-gedreven mogelijkheden via Fabric Data Agents: het platform blijft zich ontwikkelen om data-professionals te ondersteunen. Of je nu data engineer, analist of BI-specialist bent, deze nieuwe features helpen je om sneller inzichten te krijgen uit uiteenlopende data, en dit te doen op een gebruiksvriendelijke en beheerste manier.
Benieuwd wat deze Fabric-ontwikkelingen voor jouw organisatie kunnen betekenen, of wil je sparren over de beste datastrategie? Neem dan gerust contact met ons op. Als Microsoft-partner en Fabric-experts staan we voor je klaar om samen de volgende stap te zetten richting een meer datagedreven organisatie! Lees ook ons artikel over Microsoft Fabric dataplatform voor meer achtergrond.
