Microsoft Fabric update november 2025: Véél updates, van governance, AI-integraties tot real-time mirroring
Maarten Gerritsen
December 17, 2025
De Microsoft Fabric-update voor november 2025 is bijzonder uitgebreid en brengt verbeteringen op vrijwel alle vlakken van het platform. Van uitgebreide governance-tools voor beheerders tot krachtige AI-integraties met Microsoft 365 Copilot, en van verbeterde database-functionaliteit tot real-time data mirroring voor SAP, SQL Server en PostgreSQL. In deze nieuwsbrief lichten we de belangrijkste vernieuwingen toe voor Platform, OneLake, Databases, Data Engineering, Data Science, Data Warehouse, Real-Time Intelligence en Data Factory. Meer informatie over hoe Microsoft Fabric jouw organisatie kan helpen? Bekijk onze Microsoft Fabric diensten.
Microsoft heeft deze maand flink ingezet op het verbeteren van governance en gebruiksvriendelijkheid voor beheerders. Deze updates maken het beheren van grote Fabric-omgevingen overzichtelijker en efficiënter.
• Govern in OneLake voor tenant admins (preview): De OneLake-catalogus biedt nu een uitgebreide governance-ervaring speciaal voor Fabric-beheerders. Tenant admins kunnen in het Govern-tabblad alle gebruiksrapportages en aanbevelingen in één overzicht zien, met mogelijkheden voor cross-filtering en doorklikken. Via de Copilot-knop in dit dashboard kunnen beheerders in natuurlijke taal vragen stellen over hun data, trends ontdekken en snelle samenvattingen krijgen. Dit helpt om de data-governance en compliance binnen de organisatie effectiever te beheren.
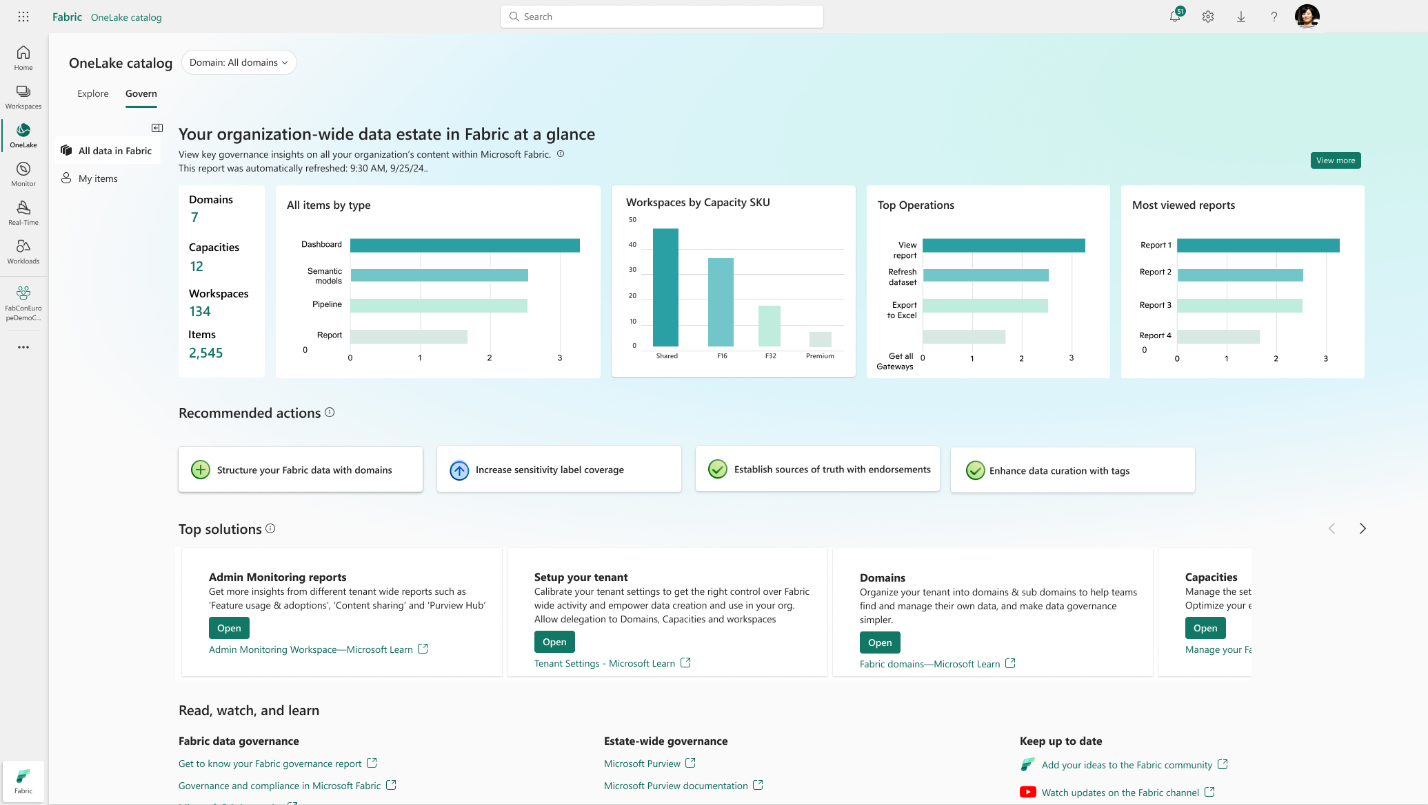
• Rechtermuisknop tab-menu voor makkelijker multitasken: Er is een nieuw contextmenu toegevoegd voor de horizontale tabbladen in de Fabric-portal. Wanneer je met de rechtermuisknop op een openstaand item klikt, kun je nu kiezen om het item in een nieuw browsertabblad te openen of om het tabblad vast te pinnen. Deze verbeteringen maken het eenvoudiger om met meerdere Fabric-items tegelijk te werken en snel te navigeren tussen belangrijke content zonder het overzicht te verliezen.
OneLake heeft belangrijke updates op het gebied van diagnostics en security die meer inzicht en controle geven over je data.
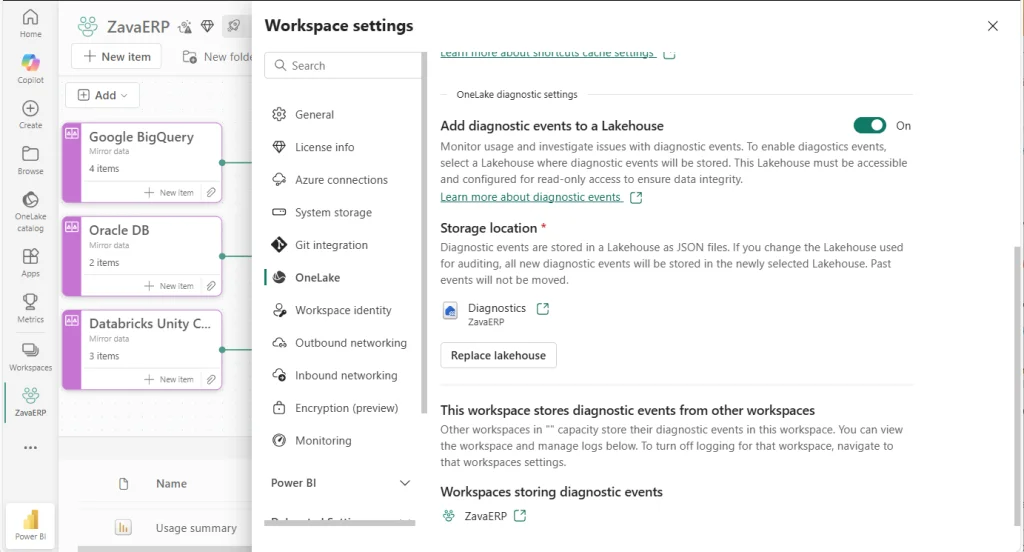
• OneLake diagnostics (algemeen beschikbaar): OneLake Diagnostics is nu algemeen beschikbaar en biedt inzicht in wie, wanneer en hoe data heeft benaderd in OneLake. Door diagnostische events vast te leggen, kun je vragen beantwoorden als "Wie heeft welke dataset geraadpleegd en op welk tijdstip?". Alle events worden als open JSON-bestanden in een gekozen Lakehouse opgeslagen. Je kunt deze logbestanden vervolgens analyseren met de tools die je al gebruikt (denk aan Spark, SQL, Eventhouse of Power BI) of zelfs externe systemen, aangezien OneLake de ADLS en Azure Blob Storage API ondersteunt. Dit betekent end-to-end zichtbaarheid en audittrail over al je data-activiteiten, wat governance en compliance op schaal vergemakkelijkt.
• OneLake security ReadWrite permissie (preview): OneLake ondersteunt nu fijngranige ReadWrite-toegang als nieuwe machtiging. Data-eigenaren kunnen hiermee specifieke gebruikers het recht geven om data te schrijven naar bepaalde Lakehouse-tables en folders zonder dat die gebruikers hogere workspace-rollen nodig hebben. Zo kun je bijvoorbeeld een gebruiker met alleen Viewer of leesrechten toch bestanden laten uploaden of tabellen laten bijwerken via Spark notebooks, de OneLake File Explorer of API's. Dit volgt het principe van minimale privileges: teams kunnen veilig samenwerken en data toevoegen zonder dat er brede beheerrechten hoeven te worden toegekend, wat de governance ten goede komt.
De database-functionaliteit in Fabric krijgt belangrijke updates voor backup-beheer, security en AI-ondersteuning.
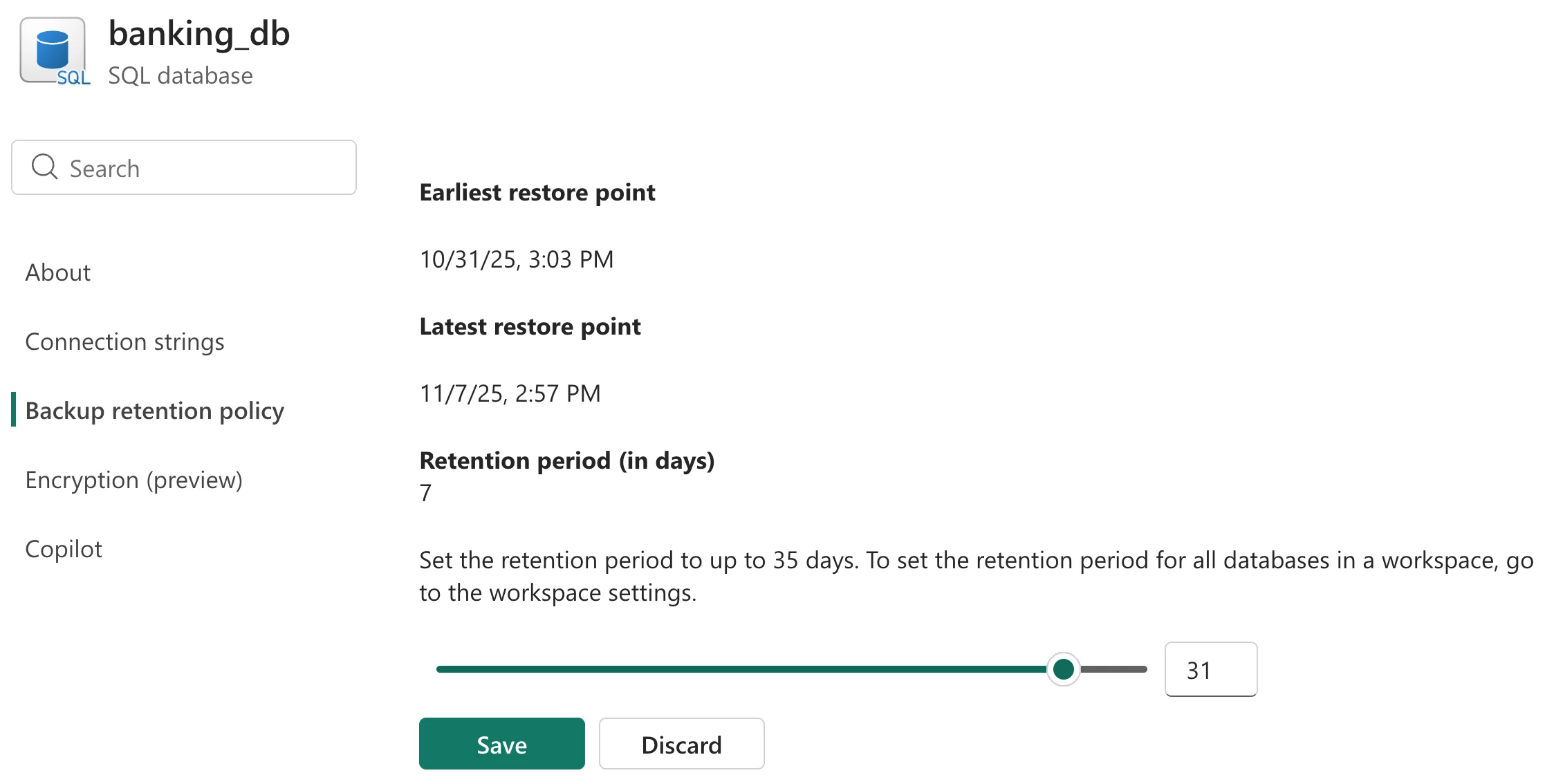
• Customizable PITR backup retention (algemeen beschikbaar): Point-In-Time Restore backups voor de SQL Database in Fabric kunnen nu flexibeler beheerd worden. Voorheen was de retentieperiode van deze continue backups standaard 7 dagen; nu kun je deze instelling aanpassen tussen 1 en 35 dagen, afhankelijk van je behoeften. Je past de retentie eenvoudig aan in de database-instellingen onder het backupbeleid. Hierdoor kun je de bewaartermijn afstemmen op je zakelijke eisen en compliance-regels: bijvoorbeeld kortere retentie voor ontwikkel/testomgevingen om kosten te besparen, of langere retentie voor productiedata ten behoeve van audits en herstelmogelijkheden.
• Customer-managed keys in SQL Database (preview): Voor organisaties met strikte compliance-eisen ondersteunt Fabric nu klantbeheerde sleutels voor database-encryptie. In preview kun je je eigen encryptiesleutels (Customer-Managed Keys) uit Azure Key Vault inzetten om gegevens in SQL Databases te versleutelen. Standaard versleutelt Fabric alle data-at-rest met Microsoft-beheerde sleutels, maar met CMK krijg je extra controle: je voldoet aan industrie-specifieke encryptiestandaarden, behoudt eigenaarschap over de sleutel (inclusief rotatie) en kunt fijner beheren wie toegang heeft. Dit biedt een extra beveiligingslaag bovenop de bestaande versleuteling.
• Nieuwe tools in Copilot chat voor SQL databases (algemeen beschikbaar): Copilot voor SQL Database heeft een grote update gekregen met interactieve hulpmiddelen in de sidecar-chat. Je kunt de geïntegreerde AI-assistent nu vragen stellen om je database te analyseren of te optimaliseren. Bijvoorbeeld: "Welke queries verbruiken op dit moment de meeste CPU?", "Geef een lijst van tabellen zonder primaire sleutel of index", of "Welke indexaanbevelingen zijn er voor mijn database?". Copilot zal direct de antwoorden en inzichten geven, zoals het tonen van heavy queries of ontbrekende indexen, en kan zelfs suggesties doen voor optimalisaties. Deze nieuwe tools helpen ontwikkelaars en beheerders om performance problemen sneller te diagnosticeren en best practices toe te passen bij het ontwerpen van de database, allemaal binnen de vertrouwde chatinterface van Copilot.
Voor data engineers brengt november belangrijke verbeteringen in connectiviteit, performance en flexibiliteit bij het werken met verschillende datasystemen.
• Spark connector voor SQL databases (preview): Er is nu een hoog-performante Spark connector beschikbaar om eenvoudig data uit te wisselen met SQL databases in Fabric. Deze library is al vooraf geïnstalleerd in de Fabric Spark-runtime, dus je hoeft niets handmatig toe te voegen. De connector maakt het mogelijk om grote dataladingen te lezen en schrijven tussen Spark en diverse SQL-doelen: Azure SQL Database, Azure SQL Managed Instance, SQL Server op Azure VM, én de nieuwe Fabric SQL-databases. Belangrijk is dat hij de beveiligingsregels op SQL-niveau respecteert, zoals object-, rij- en kolomniveau security. Ook ondersteunt hij meerdere authenticatiemethoden en schrijfmodi. Dit betekent dat data engineers Spark kunnen gebruiken voor ETL/ELT bewerkingen met SQL-bronnen, met behoud van security en op schaal.
• Snellere Notebook-load met progressive rendering: Het openen van notebooks met grote uitvoertabellen gaat nu sneller dankzij progressive rendering. Voorheen moest je wachten tot alle display()-outputs geladen waren voordat je verder kon werken; nu worden uitvoerresultaten stapsgewijs weergegeven terwijl ze binnenkomen. Je kunt dus meteen beginnen met scrollen, code bewerken en nieuwe cellen uitvoeren terwijl de rest van de resultaten op de achtergrond nog wordt gerenderd. Vooral bij data-zware notebooks of complexe visualisaties zorgt dit ervoor dat de interface responsief blijft en je productief kunt blijven zonder lange onderbrekingen.
• Nieuwe features in Fabric User Data Functions: Tijdens Microsoft Ignite 2025 zijn er nieuwe mogelijkheden toegevoegd aan de User Data Functions in Fabric. Je kunt nu een User Data Function laten uitvoeren als actie in Fabric Activator (preview), waarmee je real-time eventverwerking creëert. Daarnaast kunnen functies verbinding maken met Fabric Variable Libraries voor environment-specifieke configuraties, en veilig secrets uit Azure Key Vault ophalen. Dit maakt functies krachtiger en veiliger tegelijk.
• Azure Artifact Feed in Fabric Environment (preview): Fabric Environments ondersteunen nu het installeren van Python-packages direct vanuit een Azure Artifact Feed (privé package repository). Via de Fabric Connections kun je een nieuwe cloud-verbinding instellen van het type Azure Artifact Feed. Nieuw is een inline YAML-editor in de Fabric-omgeving waarin je rechtstreeks je environment.yml kunt bewerken. Dit maakt het beheer van eigen Python libraries een stuk eenvoudiger en veiliger: teams kunnen nu op schaal hun privé packages deployen binnen Fabric, zonder handmatig machines te configureren.
De Data Science-mogelijkheden krijgen een enorme boost met uitgebreide AI-integraties, Microsoft 365 Copilot-koppeling en verhoogde limieten voor Data Agents.
• Verhoogde limieten voor voorbeeldquery's en instructies: Data Agent makers hebben nu meer ruimte om hun agentgedrag te configureren. De limiet voor Data Source Instructions (beschrijvingen en richtlijnen voor je data) is verruimd van 5.000 naar 15.000 tekens. Ook kun je nu uitgebreidere Example Queries definiëren: de limiet daarvoor is omhoog gegaan van 1.000 naar 5.000 tekens. Deze verruimingen betekenen dat je veel meer context, schema-uitleg, zakelijke logica en voorbeeldvragen kunt meegeven aan je Fabric Data Agent. Met rijkere instructies en voorbeelden zal de agent gebruikersvragen nauwkeuriger interpreteren en antwoorden geven die beter aansluiten op de bedoeling.
• Fabric AI Functions verbeteringen (algemeen beschikbaar): De AI-functies in Fabric (zoals ai.extract(), ai.classify(), ai.generate_response()) zijn nu algemeen beschikbaar en voorzien van diverse enhancements. Je kunt nu bijvoorbeeld met de parameter response_format bij ai.generate_response() de vorm van de output specificeren, of met instructions extra context meegeven aan ai.summarize(). Praktijkvoorbeeld: een klantenservice kan deze functies gebruiken om automatisch samenvattingen van gesprekken te genereren. Met één regel code zou je bijvoorbeeld alle lange supportcalls kunnen laten samenvatten zodat per gesprek een korte conclusie en follow-up acties worden vastgelegd, in plaats van dat een medewerker dat handmatig moet doen.
• MCP Server-ondersteuning in Fabric data agents: Fabric Data Agents ondersteunen nu het Model Context Protocol via Managed MCP Server endpoints. Dit houdt in dat een Fabric data agent zijn vraag-antwoordmogelijkheden beschikbaar kan stellen aan externe AI-systemen. Andere applicaties of diensten kunnen via een MCP-interface vragen stellen aan de data agent en zo putten uit de rijke, door de agent gecureerde kennis die in OneLake is ontsloten. Deze verbetering maakt het gemakkelijker om Fabric's vraag-antwoord functionaliteit te integreren in eigen chatbots, voice assistants of andere AI-gedreven toepassingen.
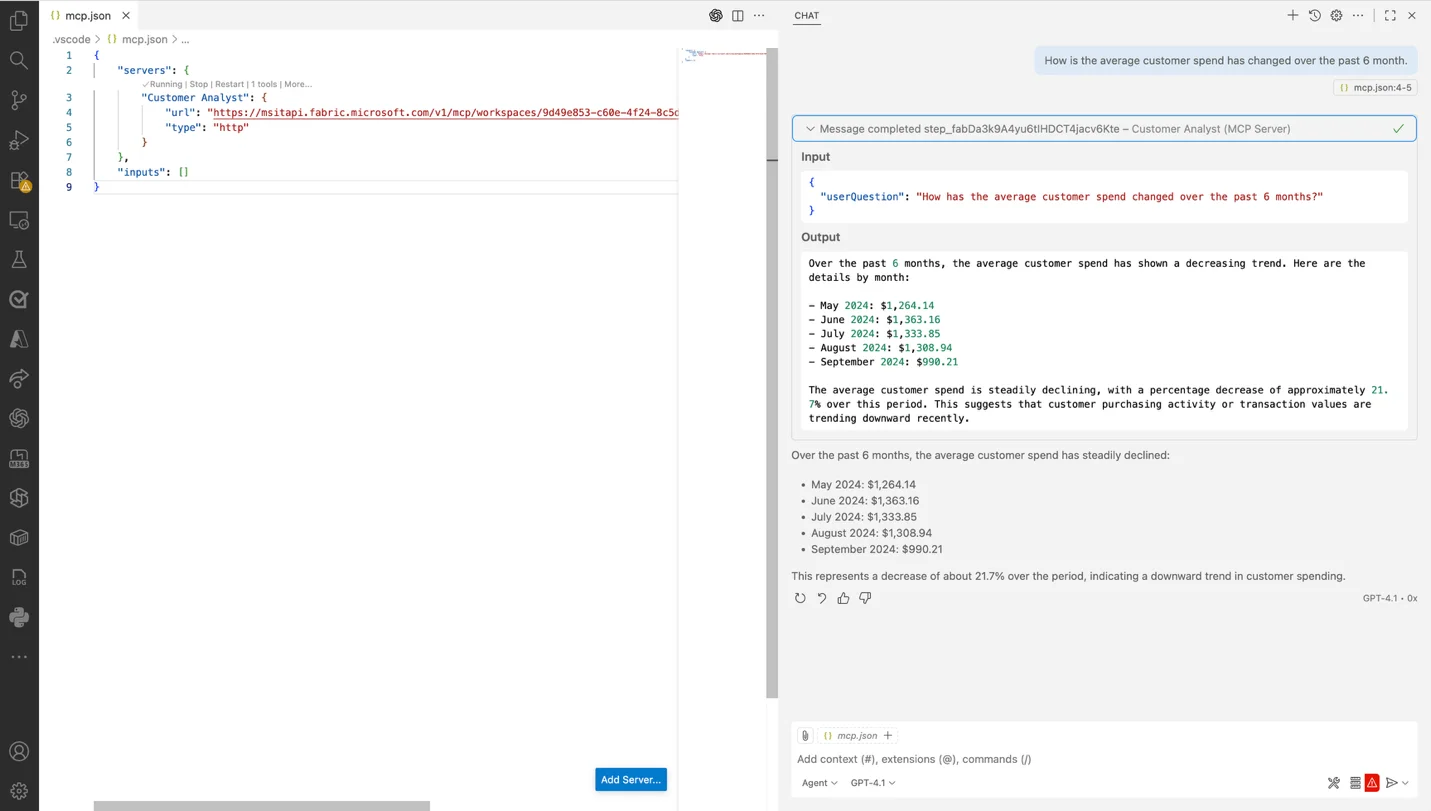
• Integratie van data agents met Microsoft 365 Copilot: Een highlight voor enterprise gebruikers: Fabric data agents zijn nu geïntegreerd met M365 Copilot. Dit betekent dat wanneer je in bijvoorbeeld Teams, Outlook of andere Microsoft 365 apps een vraag stelt aan Copilot, deze (indien geconfigureerd) ook in staat is om jouw bedrijfsdata in OneLake via de Fabric data agent te betrekken bij het antwoord. In de praktijk kun je dus binnen Office-omgevingen vragen stellen die zowel je documenten als de actuele gegevens uit bijvoorbeeld je Data Warehouse of Lakehouse omvatten. Dit slaat een brug tussen productiviteitssoftware en analyses: gebruikers krijgen in hun dagelijkse tools toegang tot up-to-date bedrijfsinformatie, zonder direct de Fabric-portal te hoeven raadplegen.
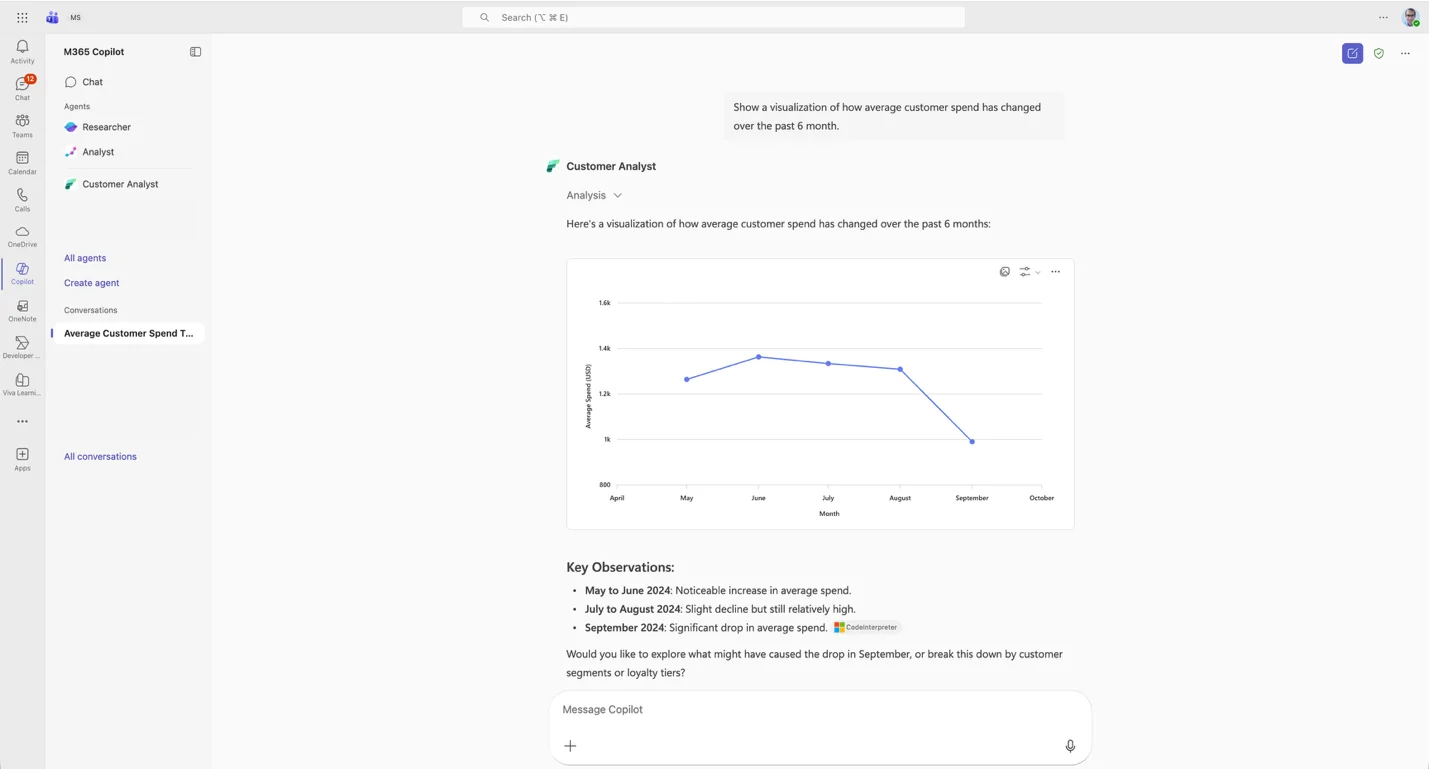
• Snellere onboarding via Data Agent entry points: Het koppelen van een Lakehouse of Warehouse aan een nieuwe of bestaande data agent is nu een fluitje van een cent. In de Fabric-interface van zowel Lakehouses als Warehouses is een nieuwe knop toegevoegd waarmee je direct een Data Agent kunt aanmaken, of jouw dataset kunt toevoegen aan een al bestaande agent. Deze in-place integratie automatiseert de nodige stappen op de achtergrond, zodat je niet meer handmatig in de Data Agent-configuratie hoeft te duiken. Met één klik wordt de data source geregistreerd bij de agent.
Het Data Warehouse krijgt krachtige nieuwe features voor performance-optimalisatie en data-integriteit.
• IDENTITY kolommen (preview): In Microsoft Fabric Data Warehouse kun je nu tabellen aanmaken met IDENTITY-kolommen (auto-increment velden). Zo'n kolom genereert automatisch unieke oplopende waarden voor elke nieuwe rij, waardoor je niet langer handmatig surrogate keys hoeft toe te kennen of zorgen hebt over dubbele sleutels. Deze functie is volledig door het systeem beheerd en werkt betrouwbaar over de gedistribueerde engine van Fabric Warehouse heen, zelfs als er meerdere laadprocessen parallel lopen. Met IDENTITY wordt het ontwerp van dimensionele modellen vereenvoudigd en verklein je de kans op key-integriteitsproblemen aanzienlijk.
• Data Clustering (preview): Er is een nieuwe preview-functionaliteit Data Clustering geïntroduceerd om query's op het Data Warehouse te versnellen en de benodigde rekenkracht te verlagen. Clustering organiseert de fysieke opslag van data op basis van overeenkomstige waarden. Concreet betekent dit dat rijen die op bepaalde kolommen vergelijkbaar zijn, gegroepeerd bij elkaar op schijf staan. Bij het uitvoeren van een query kan de engine dan hele groepen bestanden overslaan die niet relevant zijn voor de filter, waardoor er veel minder data gescand hoeft te worden. Dit "prunen" van data op bestandniveau kan aanzienlijke performancewinsten opleveren en je DWH-consumptie verlagen.
• Warehouse Snapshots (algemeen beschikbaar): Warehouse snapshots zijn nu algemeen beschikbaar in Fabric. Hiermee kun je een read-only momentopname van je volledige Data Warehouse nemen op een specifiek tijdstip. Zo'n snapshot (een soort tijdreis-kopie) kun je benaderen alsof het een gewone database is: je kunt erop connecten en er query's op draaien. Dit is ideaal om bijvoorbeeld consistente rapportages te garanderen tijdens ETL-processen. In plaats van dat dashboards halve data zien terwijl een load nog bezig is, kunnen ze tegen een snapshot van vóór de load blijven rapporteren. Met snapshots behoren fluctuerende KPI's of kapotte rapportages door tussentijdse loads tot het verleden.
Real-Time Intelligence krijgt krachtige nieuwe automatiseringsmogelijkheden met Fabric Activator en een baanbrekende operations agent.
• Geavanceerde acties automatiseren met Fabric Activator: Fabric Activator (Real-Time Hub) wordt uitgebreid met nieuwe mogelijkheden om automatisering in te richten op basis van data-events. Je kon al meldingen sturen bij bepaalde triggers, maar nu kun je nog verder gaan en direct Fabric-acties ondernemen. Bijvoorbeeld: bij een bepaalde dataconditie kun je automatisch een User Data Function laten draaien of een Spark job starten als reactie. Daarbij kun je parameters vanuit het event doorgeven aan die acties. Bovendien kun je nu custom acties definiëren via Power Automate en die hergebruiken in meerdere regels. Het versturen van Teams-berichten is ook verbeterd: je kunt nu naar specifieke groepchats of Teams-kanalen sturen, met een aangepaste boodschap en ontvangerslijst.
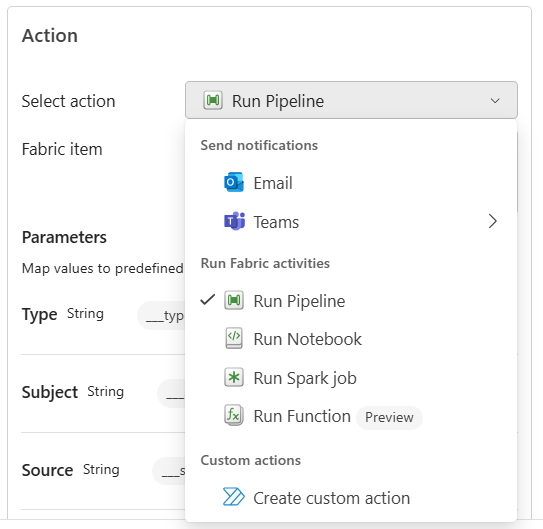
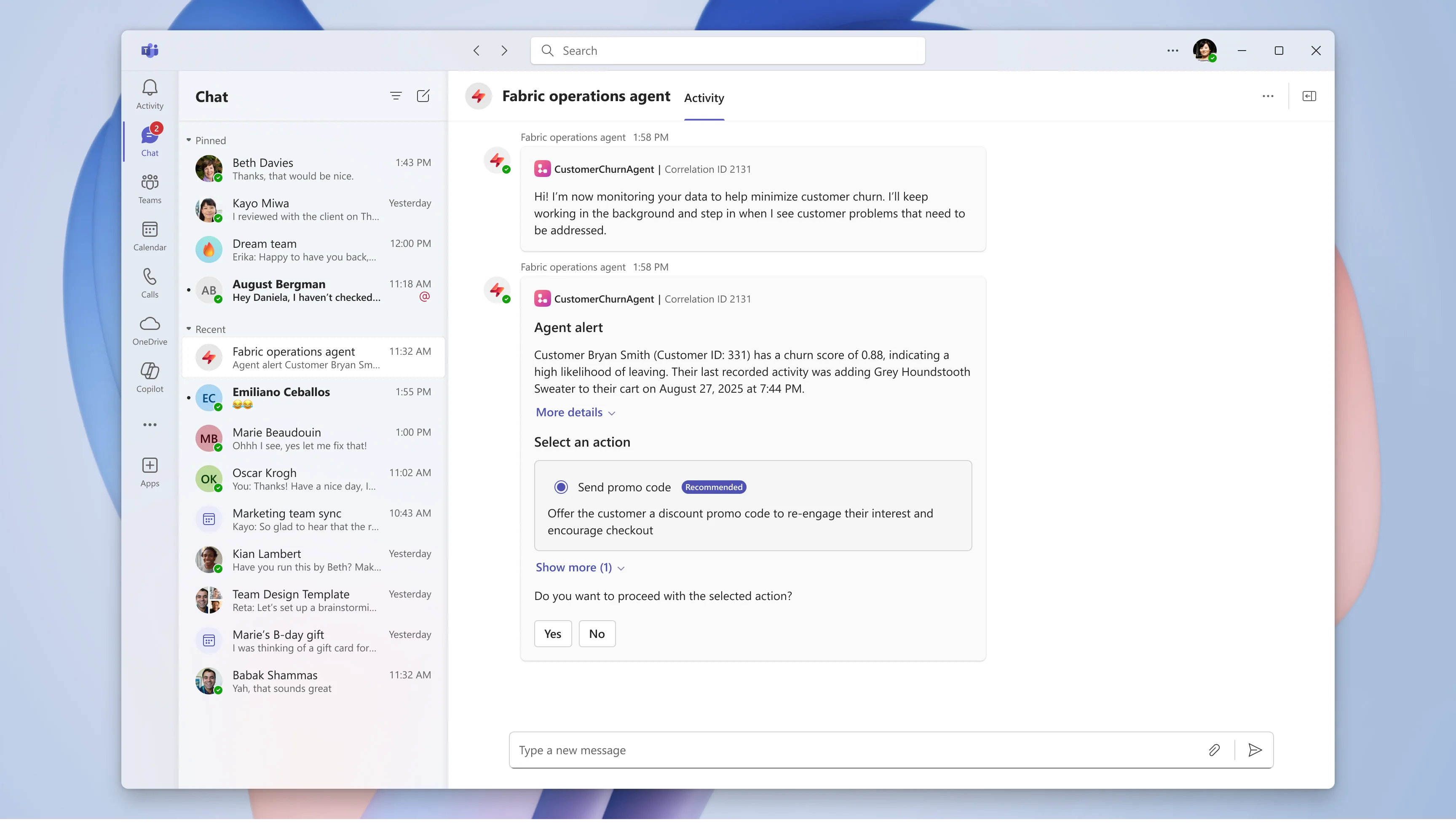
• Operations agent (preview): Een gloednieuwe toevoeging is de operations agent, een autonome AI-agent in preview die voortdurend je data in de gaten houdt en actieplannen kan voorstellen. Je stelt een operations agent in door aan te geven welke Eventhouse (KQL database) bronnen hij mag lezen, wat de bedrijfsdoelen of KPI's zijn, en welke mogelijke acties beschikbaar zijn (integraties via Power Automate). Vanaf dat moment gaat de agent zelfstandig aan de slag: hij monitort de datastromen en als er iets gebeurt wat relevant is voor de gestelde doelen, "ontwaakt" hij en bedenkt een plan van aanpak. Wanneer een bepaalde regel wordt getriggerd, genereert de operations agent een aanbeveling voor een actie, inclusief context over waarom dit nodig is. Deze suggesties worden bijvoorbeeld via Microsoft Teams gedeeld, zodat een mens kan beoordelen en bevestigen.
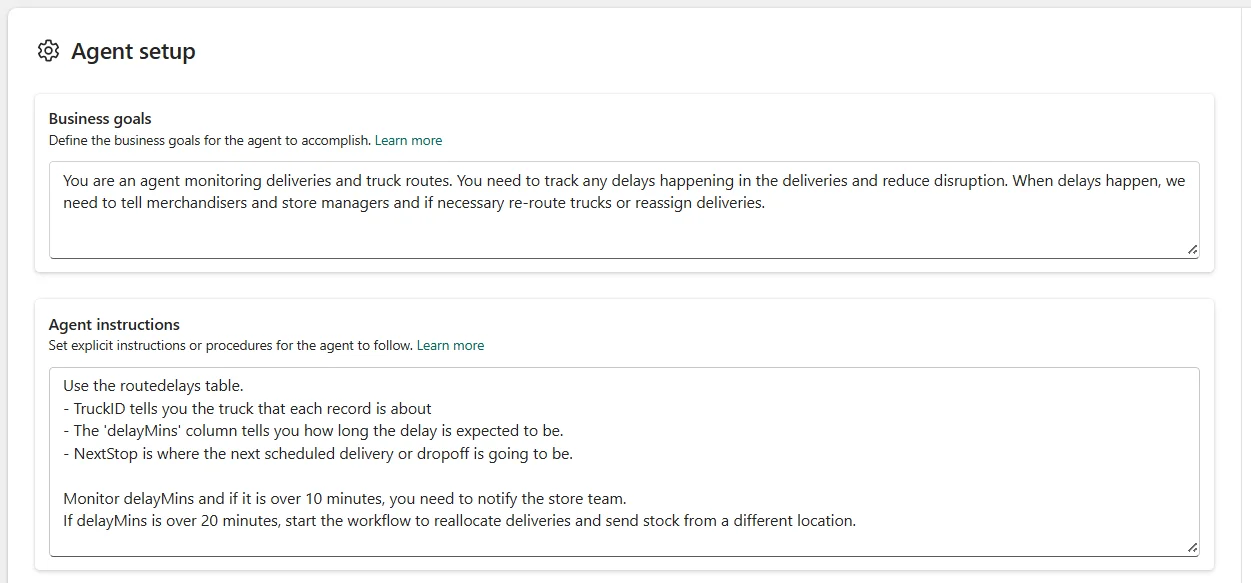
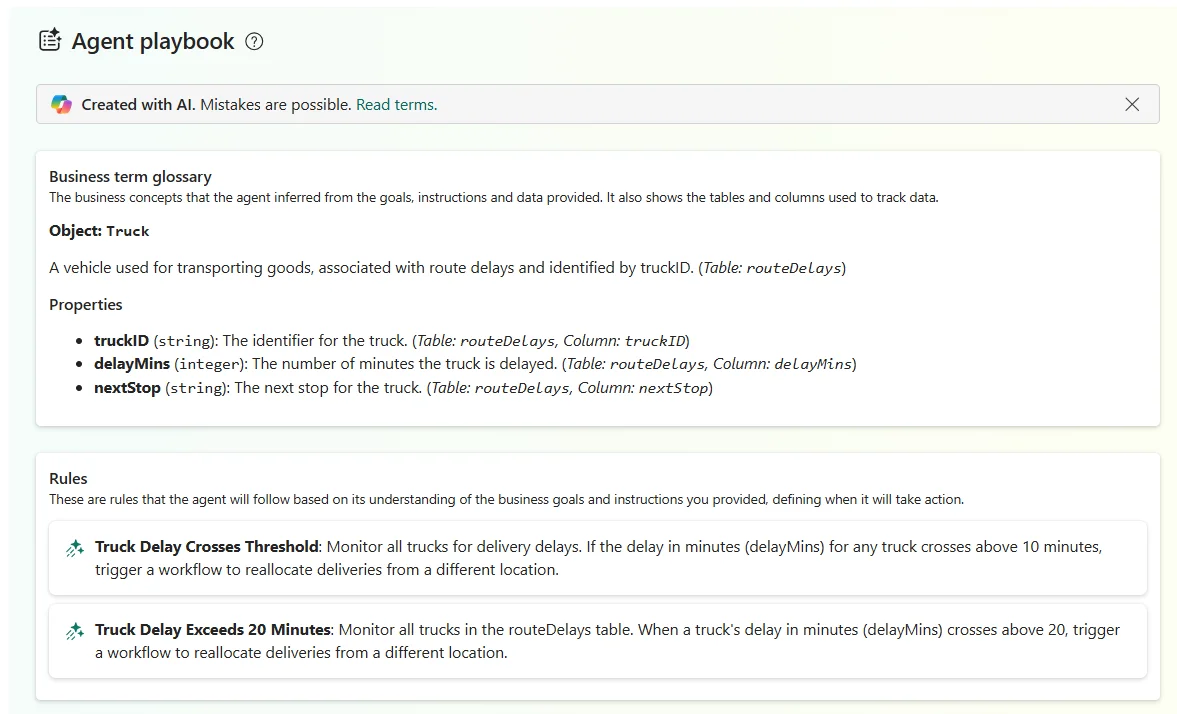
Data Factory krijgt belangrijke updates voor beheer, foutopsporing en AI-integratie.
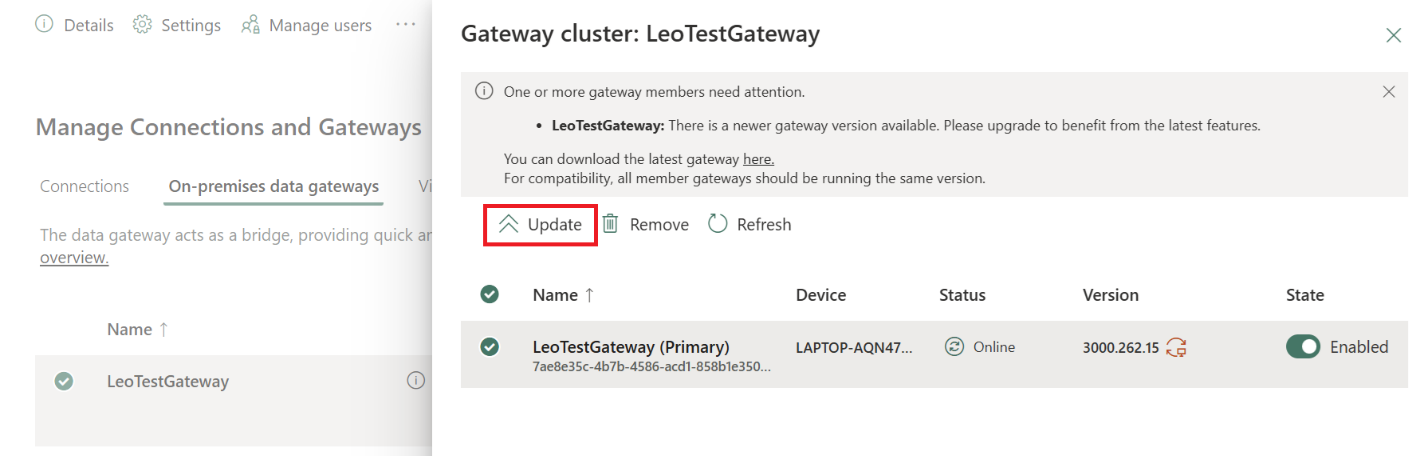
• Handmatige update voor on-premises Data Gateway (preview): Beheerders krijgen meer controle over hun on-premises Data Gateway updates. In de november-release is een preview-functie toegevoegd waarmee je zelf een gateway-update kunt initiëren, hetzij direct via de Gateway UI, hetzij geautomatiseerd via een API/script. De huidige november 2025 versie dient als baseline; vanaf december kun je dan bepalen wanneer je de gateway bijwerkt. Hiermee kun je updates plannen op momenten die uitkomen binnen jouw organisatie (bijvoorbeeld buiten kantoortijden of in een maintenanceschema) en zorg je dat de gateway altijd up-to-date en veilig is.
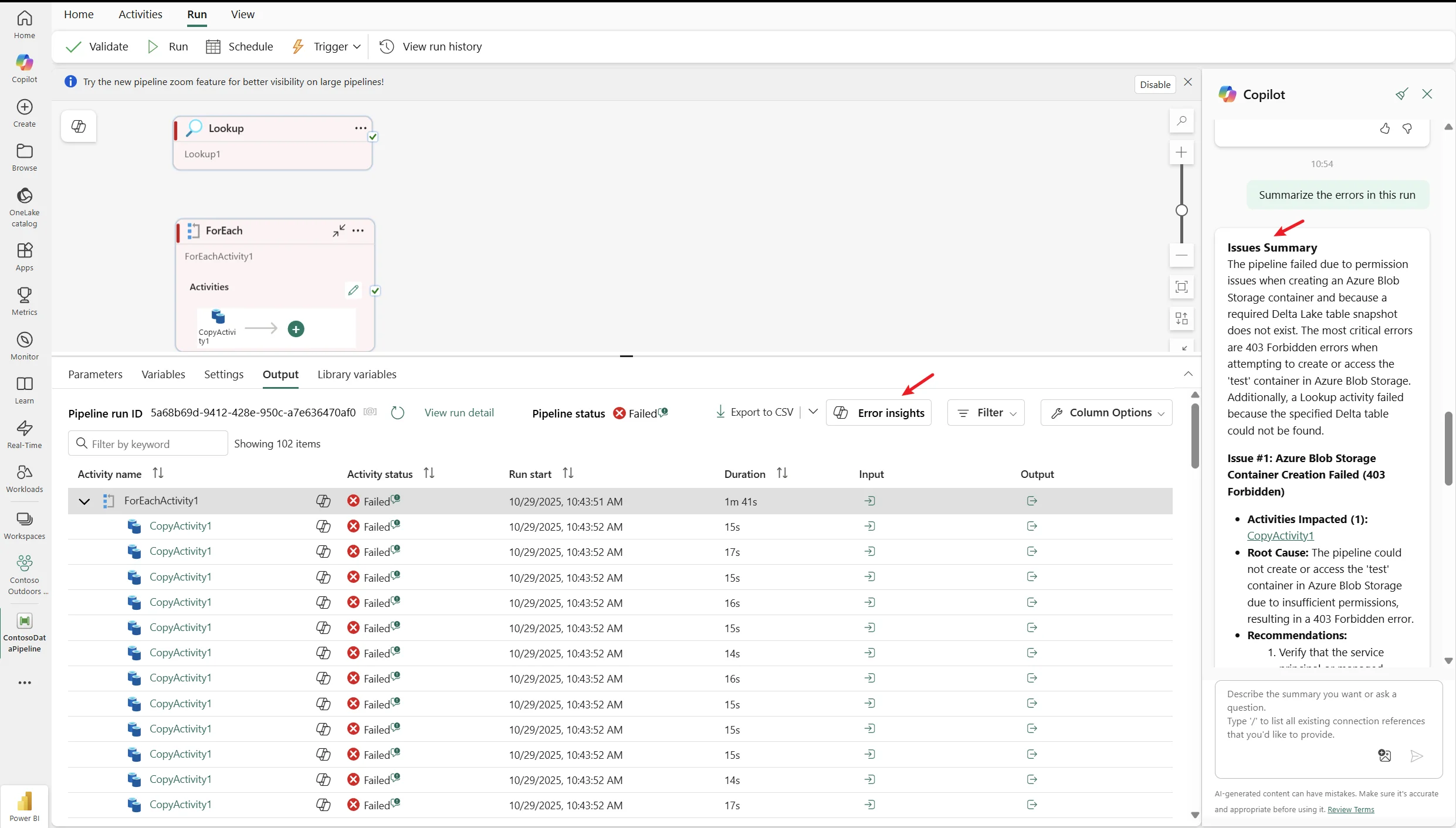
• Error Insights summary Copilot voor Pipeline: Het oplossen van pipeline-fouten is een stuk eenvoudiger geworden met de nieuwe Copilot-functionaliteit voor foutinzichten. Wanneer een pipeline-run faalt (soms met tientallen of honderden foutmeldingen), kun je nu in de Fabric Data Factory monitoring op "Error Insights" klikken. Copilot genereert dan automatisch een samenvatting van alle fouten in die run. In plaats van dat je elke error afzonderlijk moet nalopen, groepeert Copilot vergelijkbare errors, geeft per categorie een verklarende samenvatting van de oorzaak, en stelt gerichte oplossingsstappen voor. Dit bespaart enorm veel tijd en maakt het debuggen van complexe data workflows veel efficiënter.
• Integratie van Fabric AI Functions in Dataflow Gen2 (preview): Dataflow Gen2 ondersteunt nu het direct toepassen van AI-functies binnen data-transformaties. In de moderne Get Data ervaring kun je een AI Prompt stap toevoegen als je een nieuwe kolom maakt. Je schrijft in natuurlijke taal een prompt en selecteert welke kolommen uit je data als context moeten worden meegegeven. Fabric handelt vervolgens op de achtergrond het oproepen van het onderliggende Large Language Model af via de ingebouwde AI functie. Denk aan een scenario waar je klantfeedback comments hebt: je kunt een AI Prompt toevoegen die elke comment samenvat in één zin of labelt met sentiment.
• Mirroring voor SAP, SQL, PostgreSQL en Azure SQL: Microsoft Fabric breidt de Mirrored Data functionaliteit uit zodat je data uit diverse bronsystemen realtime kunt repliceren naar OneLake. Via integratie met SAP Datasphere kun je nu data uit SAP (onder andere S/4HANA, BW/4HANA, SuccessFactors, Ariba) vrijwel realtime laten mirroren naar Fabric (preview). Continuous Data Mirroring voor SQL Server 2016 tot en met 2025 is nu algemeen beschikbaar. Mirror-ondersteuning voor Azure PostgreSQL databases is nu algemeen beschikbaar, en Fabric Mirroring ondersteunt nu ook Azure SQL Database in preview. Met Mirroring voor deze bronnen kun je dus actuele operationele data vanuit diverse systemen samenbrengen in de OneLake data lake.
De november 2025 update van Microsoft Fabric is een van de meest uitgebreide tot nu toe en laat zien dat het platform volwassen wordt. Met enterprise-grade governance, krachtige AI-integraties met Microsoft 365 Copilot, real-time data mirroring voor kritische bronsystemen en autonome operations agents wordt Fabric meer dan ooit het centrale data-platform voor moderne organisaties. Of je nu beheerder, data engineer, data scientist of BI-specialist bent, deze updates helpen je om veiliger, slimmer en sneller waarde uit data te halen.
Benieuwd wat deze Fabric-ontwikkelingen voor jouw organisatie kunnen betekenen, of wil je sparren over de beste datastrategie? Neem dan gerust contact met ons op. Als Microsoft-partner en Fabric-experts staan we voor je klaar om samen de volgende stap te zetten richting een meer datagedreven organisatie! Lees ook ons artikel over Microsoft Fabric dataplatform voor meer achtergrond.
