Microsoft Fabric update juli 2025: Van Materialized Lake Views tot Copilot Agents
Maarten Gerritsen
July 31, 2025
Deze maand (juli 2025) staan er weer een aantal opvallende vernieuwingen centraal. In deze blog lichten we vijf recente updates uit die relevant zijn. Als Microsoft Fabric specialisten en Microsoft Partner zijn we bij Mount Data al volle bak aan het testen met deze nieuwe features en nemen jullie hier graag in mee!
We duiken in Materialized Lake Views (MLV) voor vereenvoudigde data-architectuur, een nieuwe integratie van de Fabric Data Agent met Microsoft Copilot Studio voor slimme AI-agents, Data Source Instructions om je AI-antwoorden nauwkeuriger te maken, de Teams-integratie in Data Activator voor geautomatiseerde alerts in kanalen, en het doorgeven van parameterwaarden (preview) in Data Activator voor nog betere trigger-acties.
Laten we beginnen met wellicht de meest besproken update: Materialized Lake Views.
Microsoft Fabric introduceert Materialized Lake Views (MLVs), een nieuwe manier om data pipelines te bouwen met SQL in plaats van complexe code. MLVs zijn gematerialiseerde views in OneLake die automatisch door Fabric worden beheerd. Ze maken het eenvoudiger om een medallion-architectuur op te zetten (de Bronze, Silver, Gold lagen voor ruwe, opgeschoonde en verrijkte data) zonder dat je ingewikkelde ETL-pipelines of Spark notebooks hoeft te schrijven.
Je definieert simpelweg in SQL hoe elke laag eruit moet zien, en Fabric doet de rest: van het materialiseren van de view tot het bijhouden van lineage en monitoring van de resultaten.
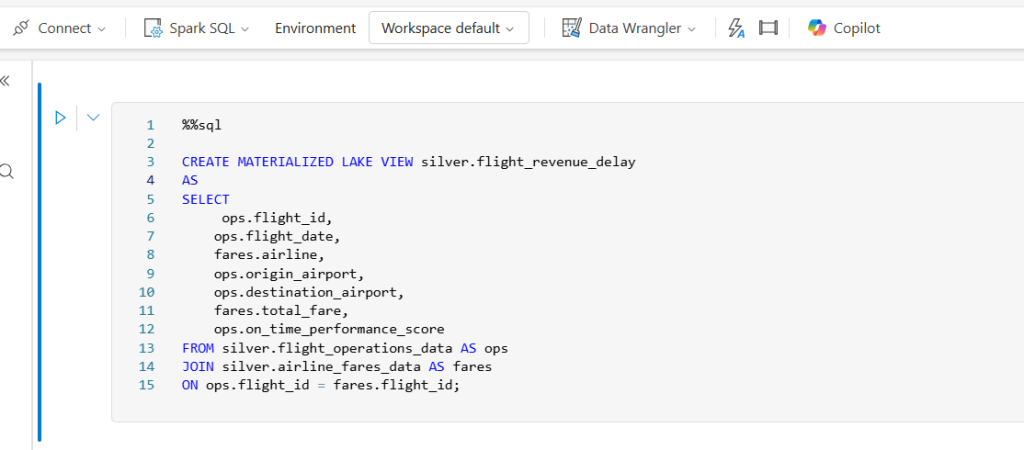
CREATE MATERIALIZED LAKE VIEW statement dat beschrijft wat de beoogde transformatiestap is, niet hoe deze technisch uitgevoerd moet worden. Dit verlaagt de complexiteit en laat ontwikkelaars focussen op de logica.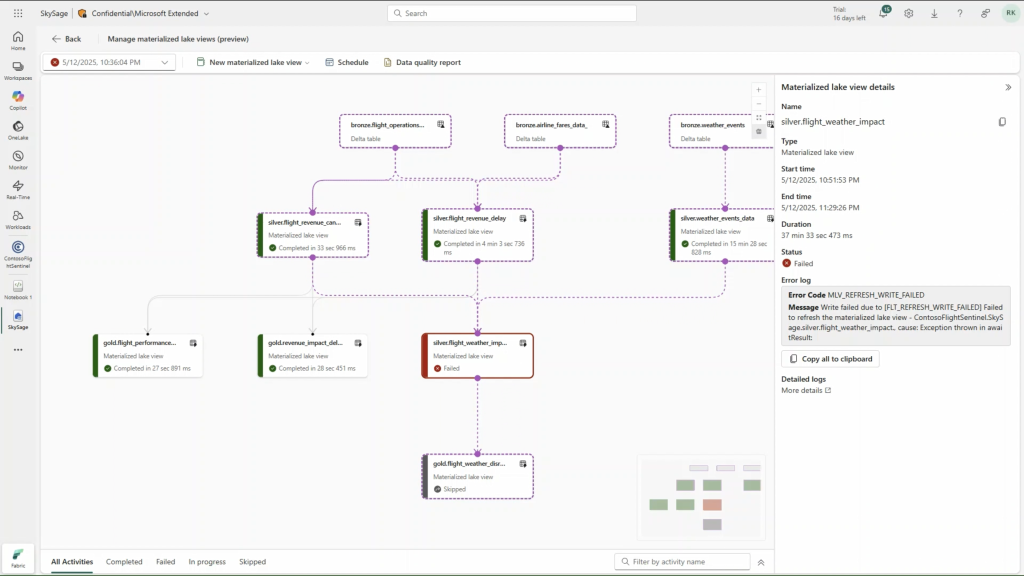
Een andere highlight deze maand is de integratie van de Microsoft Fabric Data Agent met Microsoft Copilot Studio. Copilot Studio is een platform waar je op een laagdrempelige, grafische manier je eigen AI-agents (Copilots) kunt bouwen die natuurlijke taal begrijpen, vragen beantwoorden en zelfs acties uitvoeren.
Denk aan een chat-assistent die je in Teams kunt stellen: "Wat was de omzet vorige week?" of "Plan een reminder voor budgetoverschrijding". Dankzij de nieuwe koppeling kun je nu een Fabric Data Agent toevoegen als connected agent in zo'n Copilot. Hiermee krijgt de AI toegang tot jouw data via Fabric, uiteraard veilig en volgens rechten, zodat de antwoorden die de Copilot geeft gegrond zijn in de bedrijfsdata en context.
Deze samenwerking tussen Copilot en Data Agent luidt een nieuw tijdperk van multi-agent orchestration in, waarin meerdere intelligente agents in tandem kunnen opereren. Je custom Copilot (bijvoorbeeld een virtuele assistent voor financiële vragen) kan tijdens een gesprek automatisch de Fabric Data Agent inschakelen om een specifieke datapunt op te halen of te berekenen, en die informatie vervolgens verwerkt teruggeven aan de gebruiker. Dit maakt de antwoorden van de Copilot een stuk krachtiger: completer, actueel en toegespitst op de bedrijfssituatie.
Bovendien kun je de antwoorden van zo'n AI-agent direct laten terugvloeien naar de plek waar je ze nodig hebt. Je kunt de custom Copilot met deze data-integratie namelijk inzetten in chatinterfaces zoals Microsoft Teams of zelfs binnen Microsoft 365 Copilot. Je krijgt daarmee de combinatie van een chatgesprek met een AI-assistent, en data-gedreven output.
Stel je voor: een gebruiker vraagt in een Teams-kanaal aan de bedrijfs-Copilot "Geef de actuele verkoopaantallen van product X ten opzichte van vorige week". De Copilot herkent dit als een datavraag, schakelt op de achtergrond de Fabric Data Agent in om de real-time verkoopcijfers uit de data lake op te halen, en presenteert in de chat direct het antwoord (bijv. "We hebben 5% meer verkocht van product X deze week vergeleken met vorige week"). Alles gebeurt binnen enkele seconden, in de context van het gesprek, zonder dat iemand zelf in de datasets hoefde te duiken. Multi-agent orchestration op z'n best!
Wanneer je Fabric Data Agents met meerdere databronnen gebruikt, komt er een nieuwe handige functie van pas: Data Source Instructions. Dit is een mechanisme om per data-bron specifieke instructies of context mee te geven aan de AI-engine die de vragen beantwoordt. Met andere woorden: je kunt de agent op bron-niveau vertellen hoe hij die data het beste kan gebruiken of interpreteren.
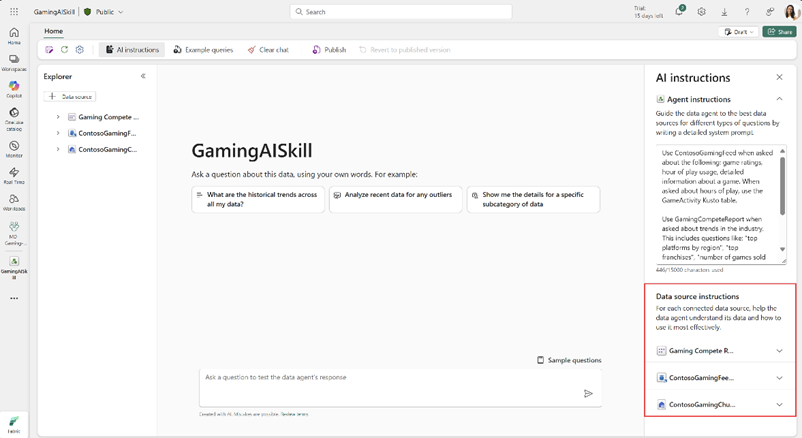
Je kunt bijvoorbeeld instellen dat voor een bepaalde bron filters standaard toegepast moeten worden, of korte beschrijvingen van velden meegeven (zodat de AI weet dat bijvoorbeeld Revenue in dataset A staat voor netto-omzet in euro's, terwijl Revenue in dataset B iets anders betekent). Ook kun je richtlijnen toevoegen, zoals "Gebruik bron X voor vragen over personeelsdata en bron Y voor verkoopdata".
Deze instructies zorgen ervoor dat de Data Agent beter weet waar hij het antwoord moet halen en hoe de data gebruikt dient te worden, wat de accuraatheid aanzienlijk verbetert.
Bij gebruik van meerdere databronnen tegelijk voorkomt dit dat de AI in verwarring raakt of verkeerde aannames doet. Je stuurt als het ware de AI: voor financiële metrics moet hij bijvoorbeeld altijd de gevalideerde Power BI dataset pakken (en niet de ruwe lakehouse tabel), of "indien zowel bron A als B relevant lijken, kies bron A want die is leidend". Hiermee reduceer je dubbelzinnigheid en voorkom je dat het model antwoorden samenstelt uit ongeschikte bronnen.
Een voorbeeld om het concreet te maken: stel je hebt zowel een datawarehouse-tabel Sales_Europe als Sales_US en een overkoepelende dataset GlobalSales. Als iemand de vraag stelt "Wat was de totale omzet vorig kwartaal?", kan de AI met goede Data Source Instructions leren dat hij direct GlobalSales moet gebruiken voor het totaal (in plaats van zelf Europe en US bij elkaar op te tellen, of erger nog dubbel te tellen).
Je kunt instructies instellen als: "Voor vragen over totale (wereldwijde) verkoopcijfers, gebruik de GlobalSales dataset; voor regionale vragen, gebruik de betreffende regionale tabel." Zo'n nuance zorgt ervoor dat de agent exact uit de juiste bron put, wat de betrouwbaarheid van zijn antwoord verhoogt. Dit soort bron-instructies vormen dus een extra laag governance over je AI-antwoorden. Onmisbaar in omgevingen met diverse data.
Automatisering houdt niet op bij data verwerken; het gaat ook om direct actie ondernemen op inzichten. Microsoft Fabric Data Activator is de component in Fabric die continu data monitort en kan triggeren op bepaalde patronen of drempelwaarden (vergelijkbaar met real-time alerts). Nieuw is dat Data Activator nu nog beter geïntegreerd is met Microsoft Teams: je kon altijd al berichten versturen naar een persoon, maar je kunt nu ook automatisch berichten laten sturen naar Teams groepschats of kanalen op het moment dat een trigger afgaat.
Eerder kon Activator alleen personen notificeren (via de Data Activator app in Teams), maar met deze update kun je een heel team of afdeling in één keer alarmeren binnen hun vertrouwde samenwerkingsomgeving. (Let op: vooralsnog worden alleen gedeelde Teams-kanalen ondersteund; privé-kanalen worden niet getoond als optie.)
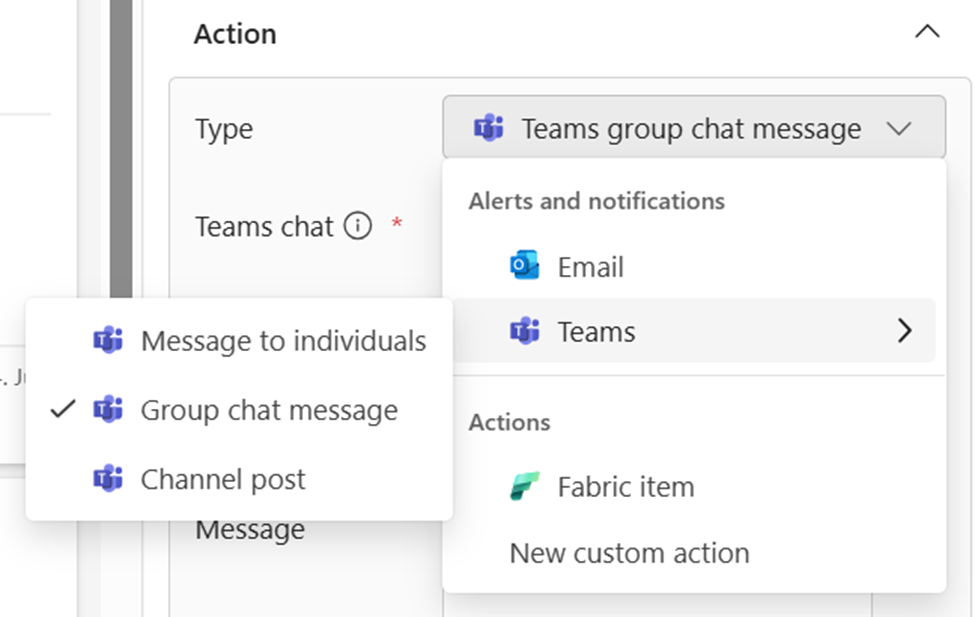
Hoe past dit in geautomatiseerde workflows? Stel, je hebt een regel ingesteld dat wanneer de verkoop in een bepaalde regio met meer dan 10% daalt week-over-week, er een actie moet plaatsvinden. In plaats van alleen een e-mailtje of logging, kun je nu een Teams-bericht laten sturen naar bijvoorbeeld het Sales EMEA kanaal in Teams, met een tekst als: "⚠️ Data Activator Alert: De omzet in regio X is deze week 12% gedaald t.o.v. vorige week. Actie vereist?".
Alle leden van dat Team zien meteen de melding en kunnen direct in de thread reageren of taken uitzetten. Dit versnelt de respons enorm, men hoeft niet eerst in Fabric of e-mail te kijken; de alert komt naar hen toe, in de omgeving waar ze toch al de dag communiceren.
Het mooie is dat deze Teams-integratie ook combineert met andere acties. Data Activator kan in één regel bijvoorbeeld zowel een Teams-bericht sturen als een Fabric pipeline activeren (voor een geautomatiseerde tegenmaatregel). Zo kun je bij een bepaalde datadrempel direct twee sporen starten: 1) mensen op de hoogte brengen én 2) een geautomatiseerd proces starten om het issue te adresseren.
In dat opzicht maakt Teams-integratie je Data Activator regels veel krachtiger en waardevoller in de praktijk: het slaat de brug tussen detectie en actie ondernemen door de juiste mensen op het juiste moment te betrekken.
Deze update past perfect in het plaatje van "datagedreven organisatie": iedereen krijgt de relevante data-signalen tijdig en in context, en kan er meteen gezamenlijk op reageren. Geen silo's of vertraging meer, de data trekt als het ware aan de bel via Teams, en zet zo een keten in beweging. Automatisering ontmoet samenwerking.
Tot slot kijken we naar een technischere maar ontzettend handige verbetering in Data Activator: de mogelijkheid om parameterwaarden mee te geven aan acties die een Fabric Notebook of Data Pipeline starten (momenteel als Preview beschikbaar). Simpel gezegd kon je voorheen in Data Activator wel instellen dat een bepaalde trigger een notebook of pipeline moest starten, maar die pipeline draaide dan generiek, zonder te weten waarom hij getriggerd was of voor welke gegevens.
Met de nieuwe update kun je nu direct waarden doorgeven aan parameters van die pipeline/notebook op het moment dat de trigger vuurt.
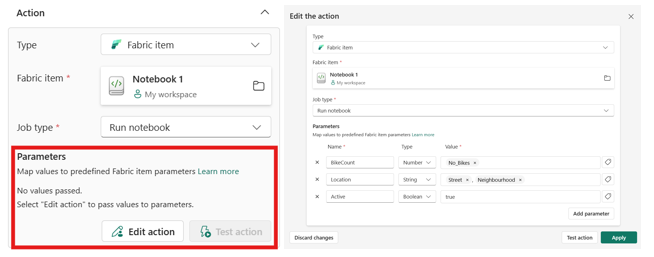
In de praktijk werkt dit als volgt: stel je hebt een Fabric Notebook gemaakt dat een bepaald rapport genereert op basis van een ingegeven productcode en drempelwaarde. Je kunt in Data Activator een regel instellen "Als de voorraad van welk product dan ook onder 100 zakt, start notebook X". Nu kun je met Pass Parameter Values daadwerkelijk de betreffende ProductID en de gemeten Voorraad meegeven aan dat notebook wanneer de regel afgaat.
In de instellingen van de Activator-actie kun je de parameternaam en -type exact invullen zoals het notebook ze verwacht, en aangeven dat de waarde moet komen uit bijvoorbeeld het veld ProductID van het event dat de trigger detecteerde. Het notebook ontvangt dan die waarde en kan specifiek voor dat product de benodigde acties ondernemen (bijv. een bestelorder plaatsen of een waarschuwing uitsturen).
Enkele voordelen:
ProductID als parameter volstaat.Met parameter-doorvoer in triggers wordt Data Activator feitelijk een stukje orchestrator dat rijke gebeurtenissen kan afhandelen. Je automatisering krijgt meer scenario-intelligentie. Deze functie staat nog in preview, wat betekent dat Microsoft graag feedback verzamelt en de mogelijkheden de komende tijd nog zal uitbreiden. Maar je kunt er nu alvast mee experimenteren.
Het instellen is intuïtief via de Activator-portal: bij het definiëren van de actie kies je de Fabric item (pipeline/notebook) en kun je daarna in een veld de parameternaam en een waarde (vast of dynamisch) invullen. Houd er rekening mee dat je parameter precies zo heet en van hetzelfde type is als wat het notebook/pipeline verwacht, anders wordt de waarde niet goed doorgegeven.
De combinatie van Teams-integraties en parameterized triggers in Data Activator betekent dat je geautomatiseerde respons op data-events nu zowel mensgericht als machinegericht kunt maken: menselijke teams krijgen meldingen op maat, terwijl tegelijk systemen geparametriseerd in actie komen. Dat is hyperautomation in actie!
De juli 2025 updates in Microsoft Fabric laten mooi zien hoe het platform volwassen wordt op alle fronten, van data-engineering tot AI-assistenten en real-time acties. Materialized Lake Views vereenvoudigen data pipelines drastisch en zorgen voor betrouwbare, governanced data in elke laag. De Data Agent integratie met Copilot Studio brengt generatieve AI en enterprise data bij elkaar, zodat iedereen in de organisatie slimmere vragen kan stellen én betere antwoorden krijgt.
Met Data Source Instructions kun je die antwoorden verder finetunen, zelfs in complexe omgevingen met veel bronnen. En tenslotte maken de verbeteringen in Data Activator het mogelijk om razendsnel van inzicht naar actie te gaan, of dat nu is via een bericht in Teams aan je collega's, of via een geparametriseerde trigger die een heel proces in gang zet.
Benieuwd wat deze innovaties voor jouw organisatie kunnen betekenen? Veel van de genoemde functies zijn als preview beschikbaar in Fabric, ideaal om mee te experimenteren. Ervaar zelf de voordelen: probeer de preview van MLVs in een test-lakehouse (je zult merken hoeveel eenvoudiger het is om een medallion-architectuur op te zetten), of bouw een eigen Copilot-agent in Copilot Studio en koppel een Data Agent om in natuurlijke taal je datavragen te beantwoorden.
Ga ook aan de slag met Data Activator alerts naar Teams en het doorgeven van parameters, zo ontdek je hands-on hoe je datagestuurde workflows nóg slimmer kunt maken.
Voor meer inzicht in hoe Mount Data als Microsoft Partner en specialist in Fabric organisaties helpt met Microsoft Fabric implementaties, of als je vragen hebt over deze updates, neem gerust contact met ons op. Ook bieden we ondersteuning voor bestaande data- en BI-projecten bij de implementatie van deze nieuwe functionaliteiten.
Kortom, Microsoft Fabric blijft in beweging. Mis deze kansen niet en neem een voorsprong met de nieuwe updates van juli 2025!
Bron: Fabric July 2025 Feature Summary | Blog Microsoft Fabric | Microsoft Fabric
